
Jobs Insights Project
Infrastructure & Architecture
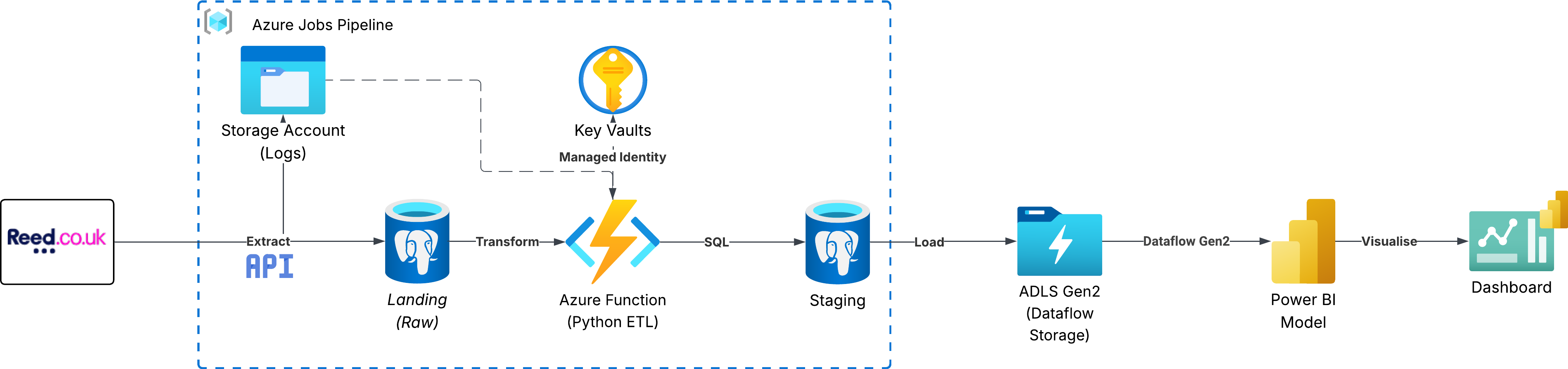
Project background
With this project, I wanted to both demonstrate a broad range of data and BI skills and gain practical insights into the job market to support my own career transition.
Data selection
Initially, I considered using sample datasets from Kaggle or Hugging Face, but after researching publicly available options, the Reed.co.uk API stood out as a richer, more realistic source for a project centred around analytics, ETL, and reporting.
Skills demonstration
I designed this project as a way to deepen my practical experience with Python, ETL development, cloud services, and end-to-end data pipeline design. The goal was to build something real and production-like, rather than follow isolated tutorials.
To accelerate development and expose myself to best-practice patterns, I used GitHub Copilot within VS Code. Copilot helped generate scaffolding for functions, classes, retries, pagination, and error-handling logic. However, I designed the overall architecture, data flow, transformations, and schema myself, and iteratively refined, debugged, and reworked the Python modules as my understanding grew.
Working with AI-assisted coding helped me:
- Learn Python syntax and structure more quickly
- Understand common ETL and API integration patterns
- Focus on problem-solving rather than boilerplate
- Build modular, reusable components
- Adopt better coding practices over time
As I am new to Python I don’t claim to fully understand every line of the generated code yet, I do understand the structure, flow and purpose of each component. This project was intentionally a practical learning exercise, and there are still areas particularly around advanced patterns and optimisation that I am actively developing.
Debugging, integrating, and refining the solution gave me a strong foundation, and I continue to revisit and improve sections as my fluency in Python increases.
The project provided hands-on experience with:
- API ingestion (pagination, filtering, retries, error handling)
- Python ETL workflows (Pandas, JSON parsing, cleaning logic)
- Azure Functions for scheduled ingestion
- Azure Storage Containers for raw and staged data
- Azure Key Vault for secure secret management
- PostgreSQL schema design and loading
- Dimensional modelling (fact and dimension tables)
- Power BI modelling, DAX, and semantic layer design
Although I am still strengthening my Python capability particularly around structuring larger applications and testing, this project demonstrates my ability to design solutions, learn quickly, and deliver working, cloud-based data pipelines using modern tools and BI practices.
If you are interested in looking at the code which was developed, this is available via the public repo found here - https://github.com/graemeboulton/job-insights-project